
Getting started with Spring and Coroutines - Part 2
Reactive to blocking

This is the second part of my short series about Spring and Kotlin coroutines. In the first part we learned that we can stay reactive from the controller to the repository. The only requirement was that our database driver is also reactive. When using NoSQL databases, we often have the choice of using a reactive driver. Nevertheless, many applications use Hibernate/JDBC, which does not provide a reactive driver, yet. I know that R2DBC exists but it's still not stable and it is no official driver. Luckily, Kotlin provides us with ways to bridge the gap.
Using a non-reactive database
Basically, I use the same example as in the previous article. There is a controller, a repository, and an entity. To better highlight the difference, I also introduced a service class.
The repository
The repository is as expected:
interface EntityRepository: JpaRepository<TestEntity, UUID>
A simple JpaRepository. No additional methods required.
The controller
Basically, the controller stayed the same:
@RestController
class TestController(private val service: TestService) {
@GetMapping(path = ["/entity/{id}"])
suspend fun getEntity(@PathVariable id: UUID) = service.findById(id)
}
The only difference is that we use the service and do not call the repository directly.
The service
Let's start with the way we shouldn't do it:
@Service
class TestService(private val repository: EntityRepository) {
suspend fun findById(id: UUID): TestEntity? = repository.findById(id).orElse(null)
}
If we try this our code would compile and our tests would pass. So, what's the problem you ask? IntelliJ shows a warning:
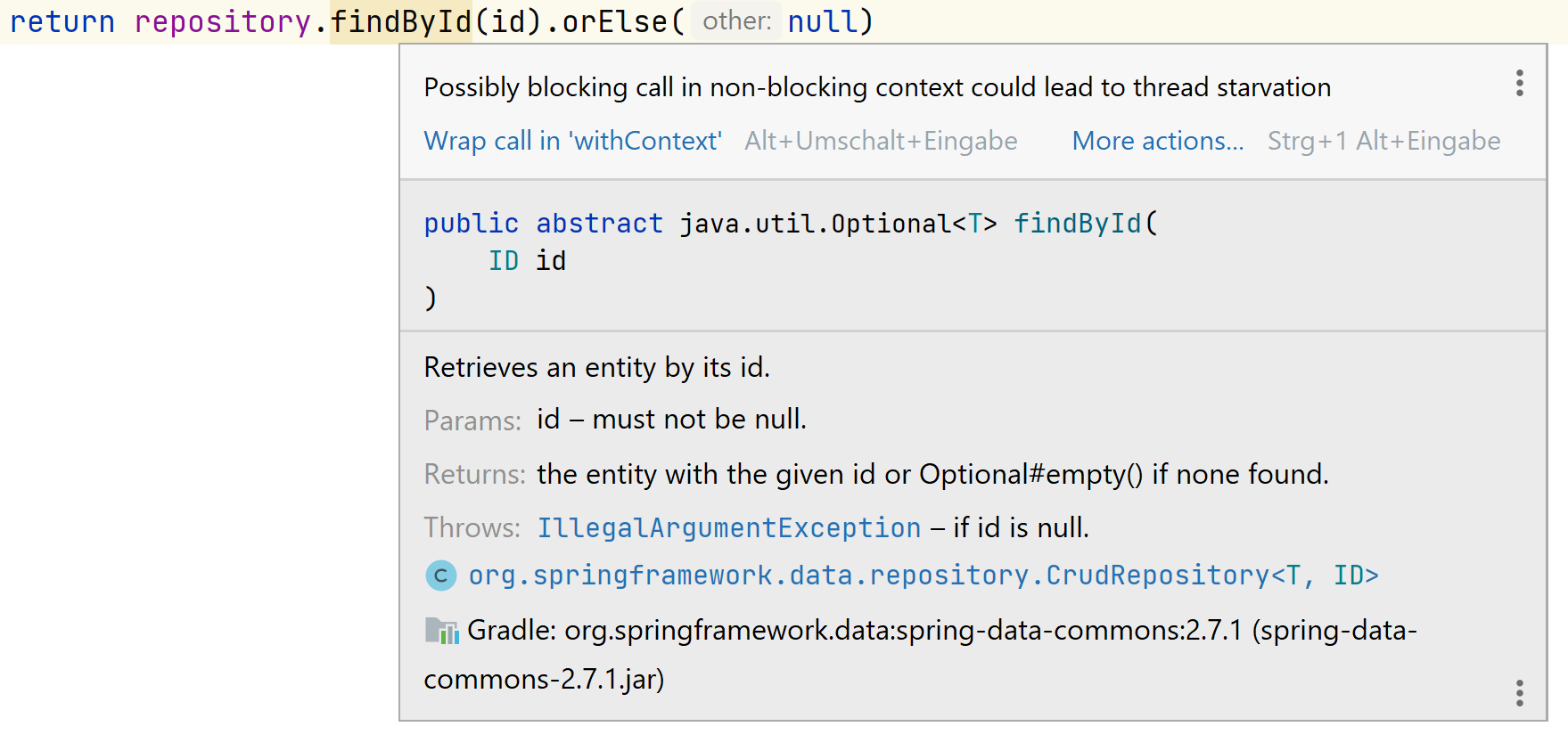
"Thread starvation", interesting, but what does this mean? We can find a good definition in the Java SE documentation:
Starvation describes a situation where a thread is unable to gain regular access to shared resources and is unable to make progress
Our coroutine calls a blocking part of the code. Because it has to block and wait for the (database) response the thread cannot perform other work. If the database never answers, the thread is always occupied and the thread-pool, where our thread originated from, lost one thread. What's even worse is that we lose our coroutine advantage. Coroutines should be non-blocking. When they wait for something, they are supposed to return the thread and wait in the background (simply put).
Let's take a look at the better solution.
IntelliJ already told us what we have to do. After applying the quick fix our service looks like this:
@Service
class TestService(private val repository: EntityRepository) {
suspend fun findById(id: UUID): TestEntity? {
return withContext(Dispatchers.IO) {
repository.findById(id)
}.orElse(null)
}
}
But what does this do? We can add some logging (I like to use io.github.microutils:kotlin-logging) to get some insights. The important part here is the thread name. Therefore, I had to adjust the logback layout a little.
When we use the non-optimal approach, we'll see this output in the service's findById() method:
2022-07-14 | 06:26:09.967 | reactor-http-nio-4 @coroutine#1 | INFO | d.c.c.TestService | Hello from findById
The important part is the third column. Our code is running in a reactor thread on coroutine number one. When using the suggested solution we get the following output:
2022-07-14 | 06:25:05.536 | reactor-http-nio-4 @coroutine#1 | INFO | d.c.c.TestService | Hello from findById outside context
2022-07-14 | 06:25:05.544 | DefaultDispatcher-worker-1 @coroutine#1 | INFO | d.c.c.TestService | Hello from findById inside context
As we can see, by switching the context, we switched the threadpool and the coroutine. By calling withContext we "returned" the Reactor coroutine. It is now free to handle other incoming HTTP requests. Our blocking code now uses a thread from the IO Dispatcher whose purpose it is to handle blocking calls. You may wonder why the DefaultDispatcher appears though we used Dispatchers.IO. We can find the solution in the Dispatcher.IO Javadoc:
This dispatcher and its views share threads with the Default dispatcher, [...]
Now that we use the new context our tests will still pass. Nevertheless, we now have a coroutine optimal solution.
Conclusion
Our main conclusion is that we should do what IntelliJ demands :-D JetBrains, being the company behind IntelliJ and Kotlin obviously knows what works best and what doesn't. Besides that, we can see that switching from non-blocking to blocking code is not that difficult with coroutines within Spring. Finally, stay tuned for my next article featuring coroutines.
As usual, you can find the complete example on GitHub.



